

 8 y7 B0 g3 d% a+ e r/ i
8 y7 B0 g3 d% a+ e r/ i


 / V9 I2 ^8 P" p- o$ ~; }' W
/ V9 I2 ^8 P" p- o$ ~; }' W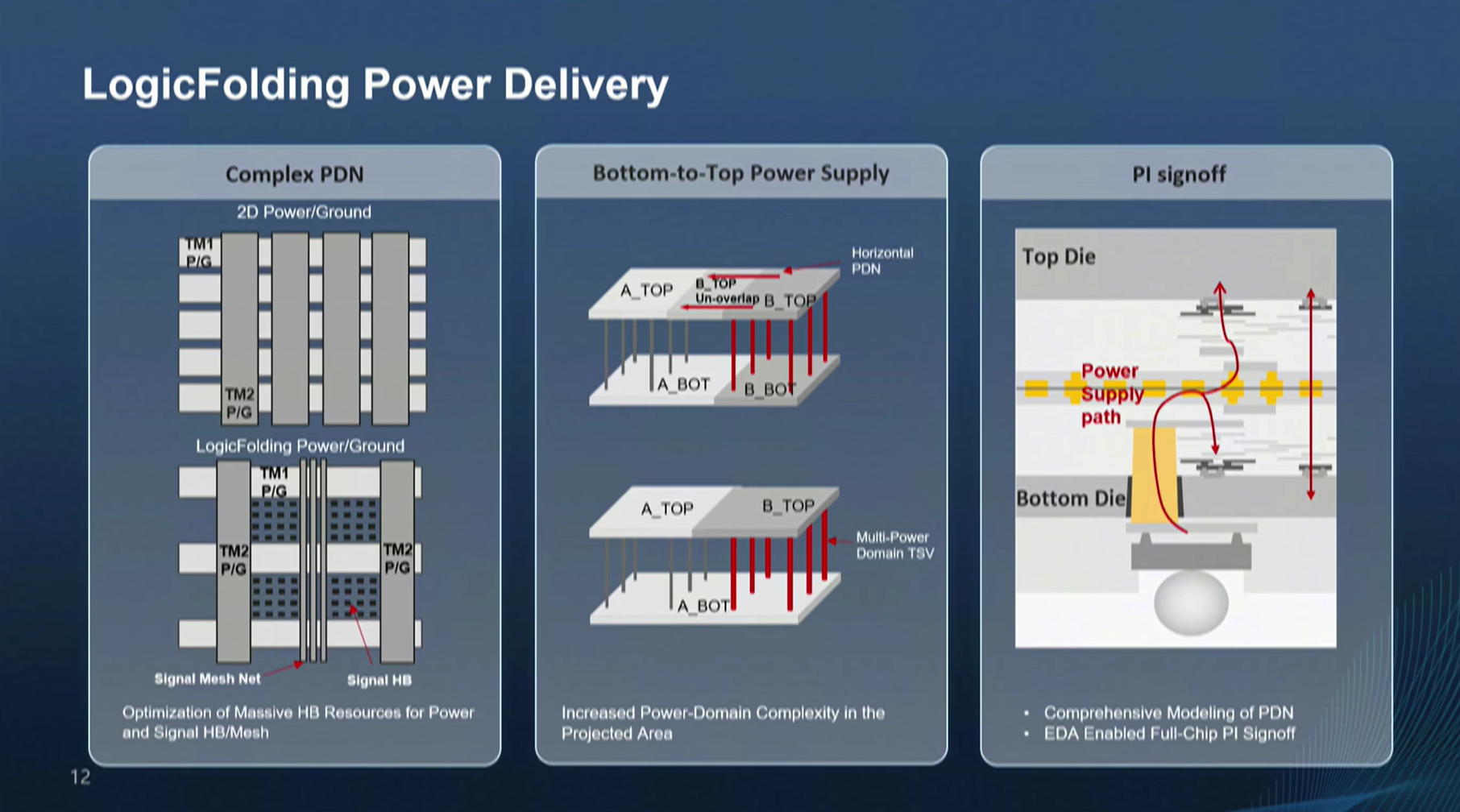
| 指标 | 相对2D的变化 |
| Die面积 | -40% |
| 主频 | +37% |
| 总功耗 | -24% |
| Buffer数量 | -56% |
| 线长 | -25% |
| 线电容 | -34% |
| 时钟树面积 | -19% |
| 时钟线长 | -28% |
| 时钟电容 | -56% |
| 核心时钟最大深度 | -42% |
| 最大Clock Skew | 135 ps → 101 ps(-25%) |
| 指标 | 2026年 | 2027年 |
| 晶体管密度(Chip Level) | +60% | +70%(2028年+80%) |
| CPU单核性能 | +15% | +44% |
| CPU多核性能 | +24% | +56% |
| GPU性能 | +38% | +87% |
| NPU性能 | +140% | +213%(绝对性能3.1倍) |
| CPU能效 | +12% | +34% |
| GPU能效 | +40% | +78% |
| NPU能效 | +81% | +118% |
 ' z) Y5 e4 I7 R; U* F
' z) Y5 e4 I7 R; U* F
 0 r# f1 t: G8 I8 {# p
0 r# f1 t: G8 I8 {# p| 指标 | Kunpeng 950 | Kunpeng 960(目标) |
| 核心频率 | ~3.2 GHz | 4.0 GHz(+54%) |
| 核心数 | 96 | 待定 |
| 金属层 | 28层(Skybridge) | 42层 |
| 堆叠方式 | 2 Die W2W HB | 3 Die |
| HTL密度 | — | >200/mm² |
| 主要瓶颈 | — | Gear Ratio需≤3 |
| 代际 | NPU数量 | 聚合带宽 | 关键特性 |
| Ascend 910C (2024) | 384 | 301 TB/s | 电互联 |
| Ascend 950 (2026) | 8,192 | 16.3 PB/s | UB + Hi-ONE |
| Ascend 960 (2028) | ~16,384 | >16 PB/s | 光学规模 |
| Ascend 990 (~2030) | 待定 | 待定 | LogicFolding进AI大Die |
| 时间 | 关键事件预测 |
| 2026 下半年 | Kirin 2026流片公布Dieshot,验证是否双层Logic结构、HB Pitch ~1.5 μm |
| 2027 | Kirin 2027量产搭载Mate 90,2层LogicFolding在小Die上形成量产曲线 |
| 2028 | Kunpeng 960实现4.0 GHz,Circuit Folding+3 Die堆叠走向成熟 |
| 2028-2029 | 首款商用真3D EDA工具链出现(国内企业占先机);3D原生IP开始商业化交付 |
| 2029-2030 | LogicFolding+3-4层堆叠在AI大Die(Ascend 990)上验证——τ定律叙事最关键的一步 |
| 2030-2031 | 全球3D逻辑堆叠成为主流设计方法之一;国产路线与全球化路线差距显著缩小 |
| 2031+ | 5nm以下制程+3D堆叠的混合方案成为现实,等效密度超越1.4nm |

Face-to-Face Hybrid Bonding(正面对正面混合键合):两片晶圆(Wafer)正面对正面,通过阵列式的铜柱(Cu Pillar)实现超高密度键合。
大黑蚊子 发表于 2026-5-28 03:47
这是搜集了资料之后让agent重新组合形成的分析文章,修改格式,上传文字和图片也是agent做的
- j4 [5 ~! w) Y! y# y7 J, j3 b* I
试了下好像感 ...
方恨少 发表于 2026-5-28 23:306 a% i0 }+ s2 }4 K! w
提问,请教蚊行,或者蚊行的牛马:
大黑蚊子 发表于 2026-5-28 08:10' S" R8 v+ l6 D& m! V
应该是第一种方法,具体怎么对齐封装咱就不知道了- w9 Z4 H9 {, |5 Q
因为华为后来说可以有效利用不同工艺生产的组件进行拼 ...
moletronic 发表于 2026-5-29 01:16
你们对华为这个吹得有点过了。。。作为Process Engineer, 俺没看出华为出了啥突破性的东西,Hybrid Bonding ...
moletronic 发表于 2026-5-29 02:379 n) ~) w) H; c9 M: H7 M' d
俺一向是很尊重华为的,而且俺认为松山湖人均水平要强过硅谷平均水平的。不过俺个人对于“革命性”‘突破性 ...
moletronic 发表于 2026-5-29 02:37
俺一向是很尊重华为的,而且俺认为松山湖人均水平要强过硅谷平均水平的。不过俺个人对于“革命性”‘突破性 ...
moletronic 发表于 2026-5-29 02:37
俺一向是很尊重华为的,而且俺认为松山湖人均水平要强过硅谷平均水平的。不过俺个人对于“革命性”‘突破性 ...
testjhy 发表于 2026-5-29 16:24
看了蚊行的解读,谈谈我的看法:
1、系统性思维:根据功能、性能、功耗等统一设计应用芯片,而不是功能芯片 ...
大黑蚊子 发表于 2026-5-29 22:431 H: }, Q- @+ t
更本质一点的话,韬定律这套东西其实是在抢夺先进工艺的定义权- Y% q8 X# L9 X" k8 i4 e1 T
从14nm之后,所谓的x nm早就不是对应物理 ...

WiFi 发表于 2026-5-28 13:098 R/ a, X" J, ~7 ^
很尊重你和可梦老弟一直以来提供的业内第一手技术解读,学了很多。这里给两位提供一个其它视角。& E0 a; ~" F' ^8 R! r }2 P
3 @- K# q: }7 k; {
我们习 ...
大黑蚊子 发表于 2026-5-29 00:105 O, C' N. _ W4 h
应该是第一种方法,具体怎么对齐封装咱就不知道了5 f! U4 |) X) `' W2 l' F6 p+ R
因为华为后来说可以有效利用不同工艺生产的组件进行拼 ...
方恨少 发表于 2026-5-28 09:30
提问,请教蚊行,或者蚊行的牛马:
方恨少 发表于 2026-5-30 04:30
第一种方法能实现也已经很逆天了。但我还是担心良率问题,虽然华为声称已经在300多款芯片上做了实验,下 ...
WiFi 发表于 2026-5-29 19:06
“大概还有政治博弈的因素”: F, l/ h8 }6 w6 a% z
我认为没有政治。海思为发表这个论文准备多半年了,因为麒麟2026芯片马上要 ...
晨枫 发表于 2026-5-30 04:53
有没有可能是将晶圆布设铜柱后对接,然后上下层同时刻电路?感觉这样才能保证对接精度? ...
方恨少 发表于 2026-5-30 04:22
这样的话虽然可以保证对接精度,但键合之后再在晶圆上布设电路的话,电路就布设在上下晶圆的外侧正反两面 ...
方恨少 发表于 2026-5-28 23:300 I- [; N; [3 e# C2 ~
提问,请教蚊行,或者蚊行的牛马:
方恨少 发表于 2026-5-30 18:22
这样的话虽然可以保证对接精度,但键合之后再在晶圆上布设电路的话,电路就布设在上下晶圆的外侧正反两面 ...
可梦之 发表于 2026-5-31 09:522 g" i$ R* @; k' G
第一种方案。先单独生产两个die,做好铜柱,然后打磨平整,face2face的键合。需要低温键合,不能超过300 ...
隧道 发表于 2026-6-1 00:11* p. _$ B1 l( u) t
这个冗余应该不是做两个靶子,而应该是把一个靶子做大。
可梦之 发表于 2026-6-1 00:13( X* U4 n% W: n S
pitch只有1.5um,铜线最大也就做到1um,偏差还有0.5um. 做大了密度就不够了。而且如果wafer平整度不够, ...
隧道 发表于 2026-6-1 00:26; @2 ~3 }7 L7 b/ ^3 c
看产品上市的性能吧。估计hw不会说细节,最终还是看产品。
隧道 发表于 2026-6-1 00:26
看产品上市的性能吧。估计hw不会说细节,最终还是看产品。
| 欢迎光临 爱吱声 (http://aswetalk.net/bbs/) | Powered by Discuz! X3.2 |